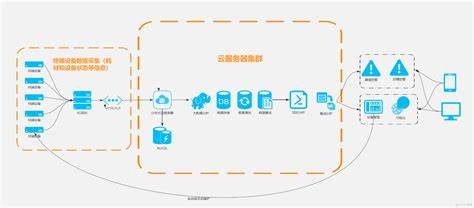
语音识别模块流程图
- 语音识别
- 2024-09-08 09:06:15
- 4777
LD3322语音识别流程图ldv7语音识别模块,目录(一)WeMos控垃圾桶开关盖(二)LDV7语音识别模块的使用基于WeMos、LDV7语音识别模块和SG90电语音识别流程分析摘要:语言识别是将类自然语言的声音信号,通过计算机自动转换为与之相对应的文字符号的一门新兴技术,属于模式识别的一个分支。
语音识别流程其中,声学模型主要描述发音模型下特征的似然概率,语言模型主要描述词间的连接概率;发音词典主要是完成词和音之间的转换。VAD端点检测我们一起来看一下语音助手中的多轮会话的主要流程。这里主要讲的是开放域中的语义顺承和略补全的实现。略补全是指当前query不结合上文时没有明显意图,但是结合上文就可以获取到意图,而语义顺承则是本轮有意图,但是
语音识别的实现通常包括预处理、特征提取和模型训练三个步骤。预处理阶段会去除背景噪声和静音部分,以提高处理的准确性。特征提取阶段会从预处理后的声音信号中提取出有用的特征,如梅尔频率倒谱系数(MFCC)等。最后,模型训练阶段会使用大量的标注数据来训练一个分类器,该分类器可以将输入的声音信号映射到相应的文本序列上。语音识别流程图描述: 1. 采集:首先,系统通过麦克风或其他设备捕捉用户的语音输入。2. 预处理:对采集到的进行降噪、增强和归一化处理,以提高步骤的准确性。3. 特征提取:从预处理后的中提取与声学特征相关的信息,如梅尔频率倒谱系数(MFCC)。4. 声学模型:使用预先训练好的声学模型将提取的特征映射到音素或字词的概率分布。5. 语言模型:根据上下文和语法规则,计算给定特










热门文章

风扇流水线自动化方范文PPT
2024-09-08 09:05:17
东北大学自动化培养计划
2024-09-08 09:05:16
非标自动化设计需要学习哪些软件
2024-09-08 09:04:55
最新现代小型自动化设备
2024-09-08 09:05:07
卷积神经网络的组成主要有什么
2024-09-08 09:05:02
产品经理常用数据分析工具包括
2024-09-08 09:04:45
自动化大一学什么课程
2024-09-08 09:04:55
自动化工程师工资如何上2万
2024-09-08 09:04:01
南京邮电大学自动化学院就业率
2024-09-08 09:03:56
自动化设备软件架构有哪些
2024-09-08 09:03:19