语音识别系统原理图解
- 语音识别
- 2024-09-29 04:06:43
- 2425
本文目录一览
语音识别技术,又称语音识别,是将语音信号转换成文本的过程。 它通过对语音的频谱和时间特征进行分析和识别来实现这一目的。
语音识别系统通常由以下几部分组成:语音捕捉器、特征提取器、语言模型和识别器。
1.语音捕捉器负责将语音信号采集并进行数字化处理。
2.特征提取器对采集的语音信号进行分析,提取有用的频谱和时间特征。
3.语言模型是用来识别语音信号的模型,它包含了语言的结构和语法规则。
4.识别器根据提取的特征和语言模型来识别语音信号,并将其转换成文本。
主要有两种语音识别技术:基于模板的识别和基于统计模型的识别。
基于模板识别是基于一个预先录入的语音样本库来识别语音,把语音信号与语音样本库中的语音信号相比较找到最相似的样本,然后将其转换为文本。
基于统计模型的识别则是根据一组语音样本建立一个统计模型,并用这个模型来识别新的语音信号。 基于统计模型的语音识别方法有基于HMM(隐马尔可夫模型),基于DNN(深度神经网络)等。 这些算法通过学习大量语音样本来建立语音模型,在识别新的语音时会根据语音模型来进行解码,并将其转换成文本。
近年来基于DNN的统计模型在语音识别域得到了广泛应用,表现出较高的识别准确率。 这类模型使用了大量的语音样本和大规模的计算资源,进行深层次的学习,能够捕捉到语音信号中更加复杂的特征.
语音识别系统的原理是什么?
根据语音识别实际应用中的不同,语音识别系统可以分为:特定与非特定的语音识别、独立词与连续词的语音识别、小词汇量与大词汇量以及无限词汇量的语音识别。 但无论哪种语音识别系统,其基本原理和处理方法大体相同。 语音识别原理语音信号输入之后,预处理和数字化是进行语音识别的前提条件。 其中,预处理主要是进行预滤波,保留正常的300~3400Hz的语音信号;数字化是要进行A/D转换及抗混叠等处理;特征提取是进行语音信号训练和识别必不可少的步骤。 能够体现语音信号特征的参数包括:(1)基于LPC的倒谱参数;(2)Mel系数的倒谱参数;(3)采用前沿数字信号处理技术的特征分析手段,如小波分析、时/频域分析、工神经网络等。 本文采用基于LPC的倒谱参数表示方法,提取出的特征值存入参考模式库中,用来匹配待识别语音信号的特征值。 匹配计算是进行语音识别的核心部分,由待识别的语音经过特征提取后,与系统训练时产生的模板进行匹配,在说话辨认中,取与待识别语音相似度最大的模型所对应的语音作为识别结果,这就是语音识别的整个过程。 语音识别技术从应用类分为特定语音识别和非特定语音识别。 特定语音识别技术是对指定的语音识别,其他的话玩具不识别,应用模式是使用前需要指定的语音训练过程,一般按照玩具提示训练2遍语音词条,然后就可以使用了;非特定语音识别是不用对指定的的识别技术,不分年龄,性别,只要说相同语言就可以,应用模式是在产品定型前按照确定的十几个语音交互词条,采集200左右的声音样本,经过我们的PC算法处理得到交互词条的语音模型和特征数据库,然后烧录到我们的芯片上,应用我们芯片的玩具就具有交互的功能了。 非特定语音识别应用有的是基于音素的算法,这种模式下不需要采集很多的声音样本,就可以做交互识别,但是缺点是识别率不高,识别性能不稳定。 在PC域,Microsoft的Word软件就有语音识别技术语音控原理是什么?
语音控功能的原理:
办公电器语音控系统总体架构框图如图1所示,它由语音采集模块、语音前级处理模块、语音训练模块、语音识别模块、语音提示模块和输出控模块组成。
(一)语音采集模块
语音采集模块主要完成信号调理和信号采集等功能,它将原始语音信号转换成语音脉冲序列,因此该模块主要包括声/电转换、信号调理和采样等信号处理过程。
(二)语音前级处理模块
语音前级处理模块的主要功能是滤除干扰信号、提取语音特征矢量,并将提取的语音特征矢量量化成标准语音特征矢量,因此该模块主要包括语音预处理、特征提取、矢量量化等语音信号处理过程。
(三)语音训练模块
语音训练模块的主要功能是将多次采集、提取的语音特征标准矢量进行概率统计,提取说话的最佳语音特征标准矢量,防止因说话心情、环境等因数引起提取特征参数不准确而影响语音识别效果,因此该模块主要包括概率统计、参数评估等处理过程,用隐马尔可夫模型(HMM模型)实现。
图1 语音控系统总体设计框图
(四)语音识别模块
语音识别模块的主要功能是将重新采集的标准语音特征矢量与语音模板库中的语音模型进行比较,判断当前语音命令功能,因此该模块主要包括矢量比较与参数评估两个过程。
(五)语音提示模块
语音提示模块的主要功能是根据语音识别的结果提示用户进行相关作或说明当前完成的功能,因此该模块主要包括调用提示语音资源文件、D/A转换、信号放大等语音处理过程。
(六)输出控模块
输出控模块的主要功能是根据语音识别的结果输出相应的控信号,实现电灯、电、风扇等办公电器的语音控功能,因此该模块主要包括信号驱动、输出控器和控对象。
(七)语音模板库
语音模板库的主要功能是存储训练后的最佳标准语音特征矢量。

语音识别技术原理是什么是什么
语音识别技术,又称语音识别,是将语音信号转换成文本的过程。 它通过对语音的频谱和时间特征进行分析和识别来实现这一目的。
语音识别系统通常由以下几部分组成:语音捕捉器、特征提取器、语言模型和识别器。
1.语音捕捉器负责将语音信号采集并进行数字化处理。
2.特征提取器对采集的语音信号进行分析,提取有用的频谱和时间特征。
3.语言模型是用来识别语音信号的模型,它包含了语言的结构和语法规则。
4.识别器根据提取的特征和语言模型来识别语音信号,并将其转换成文本。
主要有两种语音识别技术:基于模板的识别和基于统计模型的识别。
基于模板识别是基于一个预先录入的语音样本库来识别语音,把语音信号与语音样本库中的语音信号相比较找到最相似的样本,然后将其转换为文本。
基于统计模型的识别则是根据一组语音样本建立一个统计模型,并用这个模型来识别新的语音信号。 基于统计模型的语音识别方法有基于HMM(隐马尔可夫模型),基于DNN(深度神经网络)等。 这些算法通过学习大量语音样本来建立语音模型,在识别新的语音时会根据语音模型来进行解码,并将其转换成文本。
近年来基于DNN的统计模型在语音识别域得到了广泛应用,表现出较高的识别准确率。 这类模型使用了大量的语音样本和大规模的计算资源,进行深层次的学习,能够捕捉到语音信号中更加复杂的特征.












热门文章
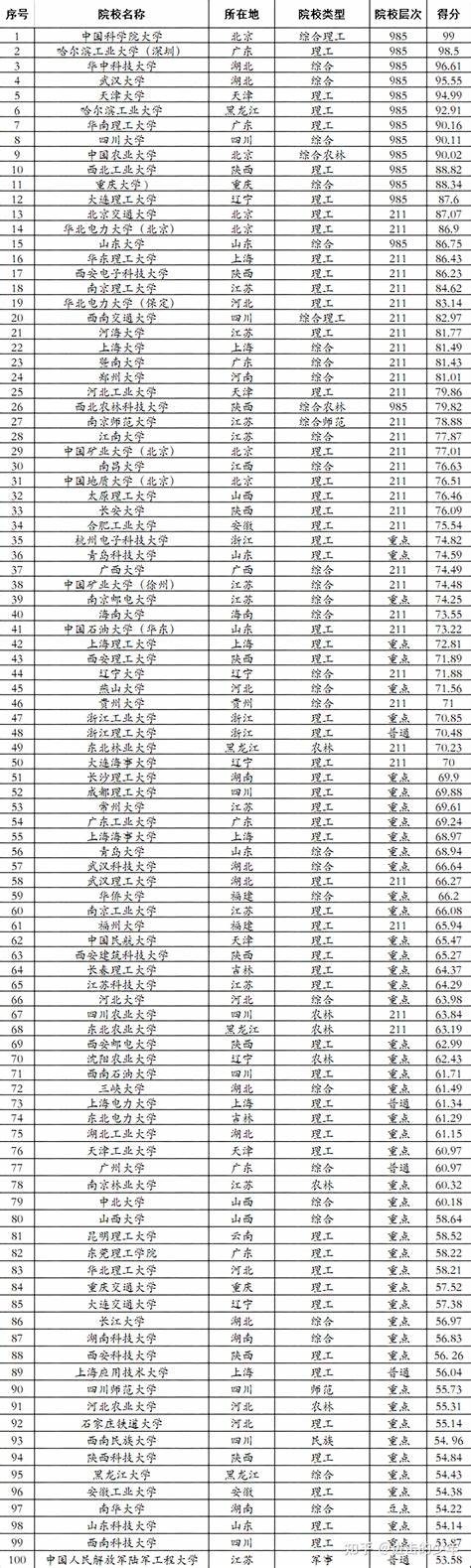
电气工程及其自动化排行榜
2024-09-29 03:34:18
python实现bp神经网络预测
2022-08-11 10:32:00
自动化专业在工程里干什么工作
2021-05-22 16:05:49
西工大自动化有前途吗
2023-04-30 11:47:48
电气工程及其自动化考研300分难吗
2022-08-22 15:49:38
工厂自动化配件价格表
2024-09-29 03:31:07
哈工程自动化专业是属于哪个系
2024-09-29 03:28:16
机械设计造及自动化好找吗
2024-09-29 03:26:36
办公自动化系统的基本知识
2021-04-02 10:52:53
沈阳自动化研究所哪个室好
2024-09-29 03:24:38