语音识别系统模型
- 语音识别
- 2024-09-22 08:56:20
- 5251
语音识别系统模型通常由声学模型和语言模型两部分组成,分别对应音节对语音的概率计算和音节转换成单词的概率计算。 本节和下一节分别介绍声学模型和语言模型技术。
声学建模HMM:马尔可夫模型概念是离散时间状态机。 隐马尔可夫模型HMM是指这个马尔可夫模型的内部状态对于外界是不可见的,只能外界看到。 。 每个时刻的输出值。 对于语音识别系统,输出值通常是为每帧计算的声学签名。 为了使用HMM来描述语音信号,需要做出两个假设:一是内部状态转换仅与先前状态相关,二是输出值仅与当前状态(或当前状态的转换)相关。 当前状态)。 这两个假设显着降低了模型的复杂性。 HMM估计、解码和训练对应的算法是前向算法、维特比算法和前向-后向算法。
语音识别中使用的隐马尔可夫模型通常对识别基元进行建模,具有从左到右的单向拓扑结构,具有循环和覆盖范围。 一个音素是一个三到五状态的HMM和一个HMM。 一个单词是组成单词的几个音素的HMM,序列化形成HMM,整个连续语音识别模型就是一个将单词和静音结合在一起的HMM。
语境建模:发音是指声音在邻近声音的影响下发生的变化。 从发声机来看,类发声器的特性只有在旋转一种声音时才能发生变化。 对于另一个声音,梯度发生变化,从而使最后一个音调的频谱与其他条件下的频谱不同。 上下文感知建模方法在建模时考虑了这种影响,使得模型能够更准确地描述语音。 只考虑前一个声音影响的叫Bi-Phone,而考虑前一个声音影响的叫Bi-Phone。 前一个和后一个声音称为Bi-Phone,称为Tri-Phone。
基于上下文的英语建模通常使用音素作为基本单位。 由于某些音素对音素具有相同的影响,因此可以通过对音素解码状态进行聚类来分离模型参数。 聚类的结果称为senon。 决策树用于实现tryphon和senone之间的有效对应。 通过回答一系列有关前后辅音类别(元音/辅音、清音/浊音等)的问题,最终确定使用哪个声母。 为其HMM状态。 采用分类回归树CART模型进行逐字发音标注。
循环神经网络(RNN)
RNN是一种用于处理序列数据的神经网络。 在语音识别中,RNN可以处理语音信号的时间序列数据,并通过学习和识别语音信号中的模式来执行语音识别。 然而传统的RNN在处理序列数据时可能会遇到梯度消失或梯度爆炸的问题。
短期记忆网络(LSTM)
LSTM是一种特殊类型的RNN,通过引入记忆块来解决传统RNN的梯度消失问题。 内存块允许网络在处理数据序列时记住期依赖关系。 这使得LSTM在解决语音识别问题时能够表现得更好。
Transformer
Transformer是一种相对较新的深度学习架构,在自然语言处理任务中表现出了极高的性能。 Transformer的优势在于其并行计算能力以及捕获输入序列中期依赖关系的能力。 在语音识别中,Transformer可以将语音信号变换为一系列特征向量,然后对这些特征向量进行码和解码,从而实现语音识别。
卷积神经网络(CNN)
CNN通常用于图像识别,但也可用于语音识别。 在语音识别中,CNN可以处理语音信号的频谱图或梅尔频率倒谱系数(MFCC)等特征。 通过卷积层,CNN可以从语音信号中提取部特征,然后通过池化层进行特征选择和信息过滤。 最后,全连接层可以将学习到的特征映射到最终的识别结果。
这些模型架构都有自己的优点,架构的选择取决于特定任务的要求和数据的特征。 未来,得益于深度学习技术的不断发展,我们有理由相信,更加高效、准确的语音识别模型架构将会出现。

上一篇:语音识别系统的模型通常由
下一篇:语音识别转文字免费












热门文章
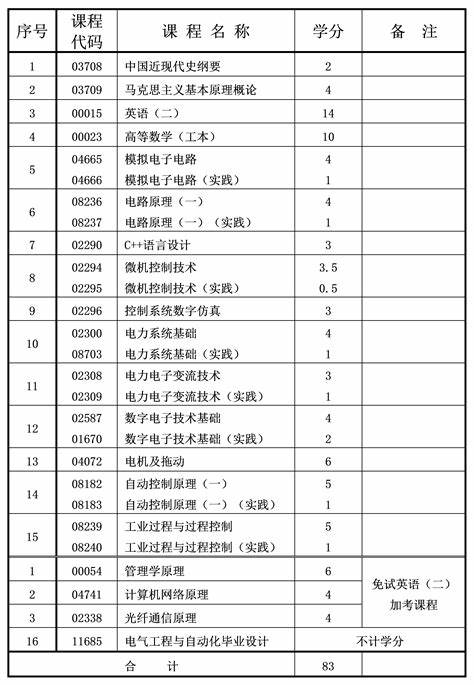
电气工程及其自动化硕士学位叫啥
2024-09-22 08:07:50
青岛理工自动化专业怎么样
2024-09-22 08:01:06
自动化32岁研究生毕业还有前途吗
2024-09-22 07:55:11
转行数据分析师 用一个月够吗
2024-09-22 07:54:00
河南自动化设备生产厂家
2024-09-22 07:54:34
东莞伟创华鑫自动化厂怎么样
2024-09-22 07:37:43
自然语言处理涉及到什么
2024-09-22 07:34:40
自动化仓储物流系统
2024-09-22 07:30:56
学自动化专业有前途
2024-09-22 07:13:52
苏州高朗自动化设备有限公司
2024-09-22 07:09:37