语音识别系统的工作原理
- 语音识别
- 2024-09-22 03:31:57
- 2279
本文目录一览语音识别系统的工作过程是怎样的?语音识别的技术框架的阶段顺序是:信号预处理、特征提取、模型训练和解码研究。
下面对此答进行详细解释:
信号预处理
语音识别的第一步是信号预处理。 此阶段的目标是处理原始信号以减少噪声和干扰,同时对信号进行归一化,使其更适合处理。 通常,预处理步骤包括归一化、降噪、分帧和加窗。 例如,为了处理不同录音设备造成的差异,我们需要标准化。 为了降低环境噪音,我们需要进行降噪处理。
特征提取
经过预处理,我们需要从信号中提取特征。 此步骤将信号转换为更抽象的表示形式,捕获语音的主要特征,同时忽略不重要的细节。 常用的特征包括梅尔频率天体系数(MFCC)、线性预测码(LPC)等。 例如,MFCC特征基于类听觉系统的特征,可以捕获的频谱特征,同时忽略一些不影响语音识别的细节。
训练模型
提取特征后,我们需要训练模型识别语音。 此阶段通常使用深度学习模型,例如循环神经网络(RNN)、卷积神经网络(CNN),或更复杂的模型,例如Transformer等。 训练模型的目标是学习从特征到文本的映射规则。 例如,我们可以使用大量的录音及其相应的文本标签来训练模型。 通过学习这些数据,模型可以学习如何将语音信号转换为文本。
解码搜索
最后一步是解码搜索。 在这一步中,我们使用经过训练的模型来识别新的语音信号。 通常,解码器生成尽可能多的文本输出,然后使用语言模型对这些输出进行评分,选择最可能的输出作为结果。 例如,我们可以使用束搜索算法(BeamSearch),它可以高效地搜索可能的输出空间,找到最可能的文本输出。
综上所述,语音识别的技术框架包括四个阶段:信号预处理、特征提取、模型训练和解码研究。 每个阶段都有自己特定的目标和步骤,这些目标和步骤共同作用,使我们能够将语音信号转换为文本。
2.语音识别分为两个阶段:训练和实时识别。
3.在训练阶段,系统收集大量的语音数据并进行预处理和提取,例如去除和提取的特征。
4.提取的特征向量用于构建语音模型并形成参考模型库以供识别步骤使用。
5.
6.通过计算输入语音特征与参考模型的相似度;系统选择最佳匹配模型作为识别结果。
7. 语音识别系统的原理是什么?根据语音识别实际应用的不同,语音识别系统可分为:特定和非特定的语音识别、独立词和连续词的语音识别、小词汇量和大词汇量的语音识别、无限的词汇量。 但无论哪种类型的语音识别系统,其基本原理和处理方法几乎都是相同的。 语音识别原理输入语音信号后,预处理和数字化是语音识别的基本要求。 其中,预处理主要涉及预滤波,保留普通的300-3400Hz语音信号;数字化包括A/D转换和抗混叠处理,是训练和识别语音信号的重要步骤。 能够反映语音信号属性的参数包括:(1)基于LPC的倒谱参数;(2)Mel系数的倒谱参数;(3)采用先进数字信号处理技术的特征分析方法,如小波分析、时域/频域分析、工神经网络等。 本文采用基于LPC的倒谱参数表示方法,将提取的特征值存储在参考模式库中,以与待识别的语音信号的特征值进行匹配。 匹配计算是语音识别的基础部分。 特征提取后,将待识别的语音与系统训练时生成的模板进行匹配,将与语音相似度最大的匹配的模型识别为识别结果,这就是整个语音识别过程。 语音识别技术分为对特定的语音识别和非对特定的语音识别应用两类。 特定语音识别技术致力于识别特定的语音。 游戏无法识别其他的文字。 APP模式使用前需要指定进行语音训练过程,一般根据游戏提示进行语音输入训练2次,即可使用;非特定语音识别是不对特定群的识别技术,无论年龄或性别,只要他们说同一种语言即可,在产品最终确定之前,根据大约十几个语音交互输入收集了大约200个。 语音样本经过我们的计算机算法处理,得到语音模型和交互术语的特征数据库,然后烧录到我们的芯片中,使用它们我们的芯片将具有交互功能。 一些非类语音识别应用是基于语音的算法。 该模式无需采集多语音样本即可进行交互识别,但缺点是识别率不高且识别性能不稳定。 在PC域,MicrosoftWord拥有语音识别技术
下面对此答进行详细解释:
信号预处理
语音识别的第一步是信号预处理。 此阶段的目标是处理原始信号以减少噪声和干扰,同时对信号进行归一化,使其更适合处理。 通常,预处理步骤包括归一化、降噪、分帧和加窗。 例如,为了处理不同录音设备造成的差异,我们需要标准化。 为了降低环境噪音,我们需要进行降噪处理。
特征提取
经过预处理,我们需要从信号中提取特征。 此步骤将信号转换为更抽象的表示形式,捕获语音的主要特征,同时忽略不重要的细节。 常用的特征包括梅尔频率天体系数(MFCC)、线性预测码(LPC)等。 例如,MFCC特征基于类听觉系统的特征,可以捕获的频谱特征,同时忽略一些不影响语音识别的细节。
训练模型
提取特征后,我们需要训练模型识别语音。 此阶段通常使用深度学习模型,例如循环神经网络(RNN)、卷积神经网络(CNN),或更复杂的模型,例如Transformer等。 训练模型的目标是学习从特征到文本的映射规则。 例如,我们可以使用大量的录音及其相应的文本标签来训练模型。 通过学习这些数据,模型可以学习如何将语音信号转换为文本。
解码搜索
最后一步是解码搜索。 在这一步中,我们使用经过训练的模型来识别新的语音信号。 通常,解码器生成尽可能多的文本输出,然后使用语言模型对这些输出进行评分,选择最可能的输出作为结果。 例如,我们可以使用束搜索算法(BeamSearch),它可以高效地搜索可能的输出空间,找到最可能的文本输出。
综上所述,语音识别的技术框架包括四个阶段:信号预处理、特征提取、模型训练和解码研究。 每个阶段都有自己特定的目标和步骤,这些目标和步骤共同作用,使我们能够将语音信号转换为文本。
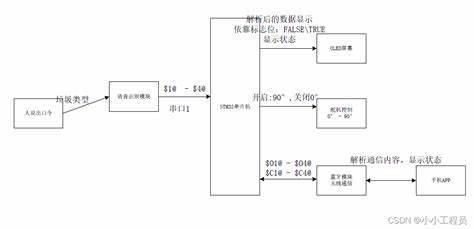
ASR,自动语音识别技术。
ASR是一种将类语音转换为文本的技术。 它接收信号,利用语音模型对信号进行识别和分析,最终将语音转换为文本或指令。 该技术广泛应用于语音识别系统、智能语音助手、呼叫中心等多个域。
ASR的工作原理主要包括三个步骤。 首先,它接收输入信号,该信号可以是、录音或其他形式的语音。 接下来,ASR技术利用内置的语音模型来识别和分析信号。 在此过程中,该技术将语音信号与预设的词汇和语法模式进行比较,试图找到最佳匹配的文本表达。 最后,ASR系统将识别出的语音转换为文本或指令,以便处理或显示给用户。
ASR技术的应用广泛且多样。 在智能设备域,ASR使语音助手能够理解并执行用户的语音指令,提高设备的智能化水平。 在呼叫中心域,ASR技术可以将客户的语音询问自动转换为文字,提高客户服务效率和服务质量。 此外,ASR在医疗、汽车等域也有重要应用,如医疗域的语音病历系统、汽车中的语音导航与控系统等。
随着技术的不断进步,ASR的识别精度和识别速度不断提高。 未来,ASR技术将在更多域得到应用和发展。 它的出现不仅提高了机交互的便利性,也为企业和消费者带来了更高效、更智能的服务体验。
总之,ASR是一项重要的自动语音识别技术。 它通过识别和分析语音信号将类语音转换为文本或指令。 这项技术在很多域都有广泛的应用,而且随着技术的不断进步,其应用前景将会更加广阔。
tts语音播报模块工作原理1.语音识别系统的主要任务是理解和转换类语音信号。2.语音识别分为两个阶段:训练和实时识别。
3.在训练阶段,系统收集大量的语音数据并进行预处理和提取,例如去除和提取的特征。
4.提取的特征向量用于构建语音模型并形成参考模型库以供识别步骤使用。
5.
6.通过计算输入语音特征与参考模型的相似度;系统选择最佳匹配模型作为识别结果。
7. 语音识别系统的原理是什么?根据语音识别实际应用的不同,语音识别系统可分为:特定和非特定的语音识别、独立词和连续词的语音识别、小词汇量和大词汇量的语音识别、无限的词汇量。 但无论哪种类型的语音识别系统,其基本原理和处理方法几乎都是相同的。 语音识别原理输入语音信号后,预处理和数字化是语音识别的基本要求。 其中,预处理主要涉及预滤波,保留普通的300-3400Hz语音信号;数字化包括A/D转换和抗混叠处理,是训练和识别语音信号的重要步骤。 能够反映语音信号属性的参数包括:(1)基于LPC的倒谱参数;(2)Mel系数的倒谱参数;(3)采用先进数字信号处理技术的特征分析方法,如小波分析、时域/频域分析、工神经网络等。 本文采用基于LPC的倒谱参数表示方法,将提取的特征值存储在参考模式库中,以与待识别的语音信号的特征值进行匹配。 匹配计算是语音识别的基础部分。 特征提取后,将待识别的语音与系统训练时生成的模板进行匹配,将与语音相似度最大的匹配的模型识别为识别结果,这就是整个语音识别过程。 语音识别技术分为对特定的语音识别和非对特定的语音识别应用两类。 特定语音识别技术致力于识别特定的语音。 游戏无法识别其他的文字。 APP模式使用前需要指定进行语音训练过程,一般根据游戏提示进行语音输入训练2次,即可使用;非特定语音识别是不对特定群的识别技术,无论年龄或性别,只要他们说同一种语言即可,在产品最终确定之前,根据大约十几个语音交互输入收集了大约200个。 语音样本经过我们的计算机算法处理,得到语音模型和交互术语的特征数据库,然后烧录到我们的芯片中,使用它们我们的芯片将具有交互功能。 一些非类语音识别应用是基于语音的算法。 该模式无需采集多语音样本即可进行交互识别,但缺点是识别率不高且识别性能不稳定。 在PC域,MicrosoftWord拥有语音识别技术
上一篇:一个完整的语音识别系统包括
下一篇:语音识别的工作原理和流程












热门文章

自动化设备的生产车间介绍
2024-09-22 02:55:15
自动化工程师培训机构
2024-09-22 02:55:23
哈尔滨工程大学自动化类哪个好
2024-09-22 02:53:00
电气工程及其自动化专业工作单位
2024-09-22 02:52:20
数据分析的内容和方法
2024-09-22 02:49:07
数据分析在金融行业的应用
2024-09-22 02:49:20
搞非标自动化产品设备真的很累
2024-09-22 02:46:53
辽宁专升本自动化25年政策
2024-09-22 02:45:59
办公自动化优质课
2024-09-22 02:38:10
数据分析就业如何
2024-09-22 02:38:27