python神经网络学习代码
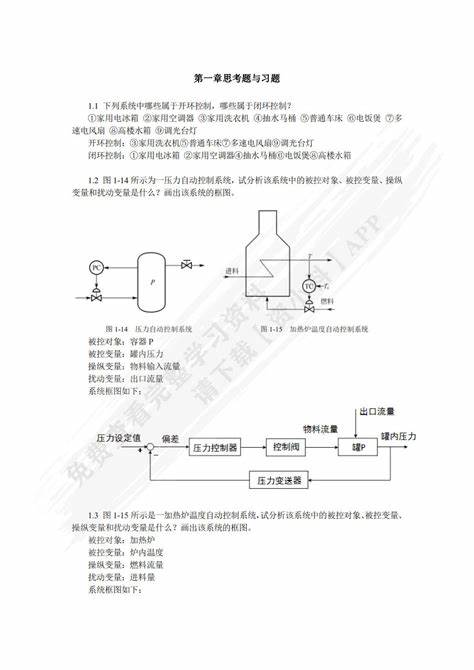
- 神经网络
- 2024-09-27 21:04:55
- 5892
一、ReLU/TanH/Sigmoid三种不同的活函数在多层全链接神经网络中的区别图示(附Python代码)
探索ReLU、TanH与Sigmoid三种活函数在多层全连接神经网络中的表现差异,通过可化方式,深入理解其各自特性。神经网络的链接情况直接影响模型性能,ReLU、TanH和Sigmoid作为活函数,其作用是引入非线性,使模型具备学习复杂模式的能力。
借助Python实现,准确描绘ReLU、TanH与Sigmoid在不同神经网络层的活情况,有助于直观理解它们的特征与适用场景。
完成模型训练后,对每一层的特征空间进行绘,直观展示ReLU、TanH和Sigmoid的活效果。
使用三维动图展示活函数在不同层的变化,有助于观察它们如何影响数据分布与决策边界。
ReLU活函数表现出快速响应与非饱和特性,其输出仅在正输入时有非零值,有助于加速梯度下降过程,避免梯度消失问题。
TanH活函数提供了-1到1的输出范围,相对ReLU而言,它具有较好的平移与缩放能力,有助于优化模型的训练过程。
Sigmoid函数虽然在早期广泛使用,但因其输出接近0或1时梯度接近于零,导致梯度消失问题,影响模型训练效率。
此份代码作业记录,虽时间久远,但体现了探索不同活函数在神经网络中的应用与影响,为学习和研究提供基础。

二、python神经网络程有什么用?
预测器神经网络和计算机一样,对于输入和输出都做了一些处理,当我们不知道这些是什么具体处理的时候,可以使用模型来估计,模型中最重要的就是其中的参数。
对于以前所学的知识都是求出特定的参数,而在这里是使用误差值的大小去多次指导参数的调整,这就是迭代。
误差值=真实值-计算值
分类器
预测器是转换输入和输出之间的关系,分类器是将两类事物划分开,只是预测器的目的是找到输出在直线上,分类器是找到输出分为两类各在直线的上下方。 但其实都是找到一个合适的斜率(只考虑简单情况下)
分类器中的误差值E=期望的正确值-基于A的猜测值得到的计算值$E=t-y\quadE=(ΔA)x$这就是使用误差值E得到ΔA
ΔA=E/x
,再将ΔA作为调整分界线斜率A的量
但是这样会存在一个问题,那就是最终改进的直线会与最后一个训练样本十分匹配,近可以认识忽略了之前的训练样本,所以要采用一个新的方法:采用ΔA几分之一的一个变化值,这样既能解决上面的问题,又可以有节地抑错误和噪声的影响,该方法如下
ΔA=L(E/x)
此处的L称之为调节系数(学习率)
使用学习率可以解决以上问题,但是当数据本身不是由单一线性过程支配时,简单的线性分类器还是不能实现分类,这个时候就要采用多个线性分类器来划分(这就是神经网络的核心思想)
神经网络中追踪信号
对于一个输入,神经元不会立即反应,而是会抑输入,只有当输入增强到了一定程度,才可以触发输出,并且神经元前后层之间是互相连接的。
神经元的输入和输出一般采用S函数(sigmoidfunction)
y=11+e−x
。 因为神经元存在多个输入,所以需要将输入的总和作为S函数的输出。 要控最后的输出结果,最有效的方式就是调整节点之间的连接强度,这就要使用到矩阵点乘。
一般神经网络分为三层,第一层是输入层,无需任何计算;第二层是隐层;最后是输出层。
总体过程如下:(特别注意:权重矩阵是不一样的)
1.输入层接收信号,通过权重比例输出到隐层,此处遵守公式
X=W•I
$$
\begin{pmatrix}
w_{1,1}&w_{2,1}\\
w_{1,2}&w_{2,2}
\end{pmatrix}
\begin{pmatrix}
input1\\
input2
\end{pmatrix}
$$其中W是权重矩阵,I是输入矩阵,X是组合调节后的信号
2.隐层使用S函数(活函数)对输入进行处理,然后输出到输出层
3.按照同样的公式,先经过权重的组合调节再适用S函数(活函数)得到最后的输出
反向传播误差
误差=期望的输出值-实际的计算值,所以根据误差来调整权重。 误差一般使用不等分误差,就是按照权重的比例分误差。
使用权重,将误差从输出向后传播到网络中,称为反向传播。
上一篇:自动化专业最吃香十大专业
下一篇:自动化检测的方法有哪些











热门文章

自己做一套自动化设备要多少钱
2024-09-27 21:02:51
电气自动化常用的知识点
2024-09-27 21:02:43
办公自动化实训总结1500字
2024-09-27 21:02:38
一家实体店铺需要做哪些数据分析
2024-09-27 21:02:34
造自动化设备报价
2024-09-27 21:01:51
自动化生产实习报告怎么写
2024-09-27 21:01:23
机械自动化实习报告四千字
2022-08-01 17:04:14
办公自动化系统属于什么软件
2024-09-27 21:01:03
35岁学不了数据分析了吗
2024-09-27 21:00:50
自动化设备总结怎么写
2021-02-25 13:20:52