自然语言处理技术发展总结
最新回答:可以通过以下方法解决问题:
登录后回复
共 3 个回答
-
预训练模型与10种常见NLP预训练模型
探索NLP预训练模型的秘密:十个关键模型解析
在人工智能领域,预训练模型就像明亮的星星,照亮自然语言处理(NLP)的广阔天空。本文将带您深入了解10种常见的NLP预训练模型,从自回归、自编码的起点到Transformer的创新,领略它们的特点和优势。
自回归与自动编码之战:GPT和BERT
GPT是OpenAI的自回归语言模型,以其生成能力而闻名。单向处理限制了信息流,适合文本生成任务。
Google的代表作BERT拥有双向处理技术,可以捕获上下文,但Mask标签的使用影响了预训练和Fine-tuning的效率。
BERT的创新和深入分析
BERT基于Transformer的Encoder,通过无监督训练,包括MaskedLM和NextSentencePrediction任务,展示了其强大的功能语义理解。
虽然参数较多,但重点关注wordembedding、positionembedding和segmentembedding,展示了复杂结构下的性能提升。
预训练任务的艺术:MLM和NSP
MaskedLanguageModel挑战模型预测隐藏词,迫使模型依赖上下文而不是孤立的单词。
NextSentencePrediction任务通过[CLS]和[SEP]标签将理解任务转换为二元分类,增强了模型的序列理解能力。
ALBERT的轻量级革命
ALBERT继承了BERT的框架。创新之处在于参数分解、NSP的共享和去除以及SOP的使用。实验结果并不详细,但稳定性和效率明显提高。
RoBERTa的优化与超越
RoBERTa通过增加训练数据、调整batchsize和动态mask进一步提升性能,并放弃了NSP任务。
预训练策略多样化
BERT的mask策略包括静态和动态,以及NSP训练的不同组合,以适应不同的场景性爱模式提供多样性。从ELMO和XLNet的自回归角度来看,ELMO解决了多义问题,XLNet通过双流注意力扩展了可能性机制。T5模型结合了NLP理解和生成,展示了预训练方法的创新。
时间轴揭示了NLP预训练模型的演变,从ELMO到BERT,再到XLNet和ALBERT,每一步都在突破NLP技术的边界。这些模型各有特点,有的专注于文本生成,有的专注于语义理解,共同推动了NLP领域的进步。
总结:
Token的作用有区别:query和content,分别携带位置和内容信息,为模型做出决策。提供关键支持。
从GPT到GPT-2的迭代,体现了Transformer技术的不断优化和规模扩张。
T5的统一框架体现了NLP预训练在语言理解和生成任务上的融合创新。每个模型都是NLP旅程中的重要里程碑。它们的结合与竞争共同推动了NLP技术的不断演进。对这些模型的深入理解无疑将为你的NLP项目提供强大的工具和灵感。如果想了解更多细节,不妨参考原论文和源代码,那里有无穷的智慧和见解。
 赞22回复举报
赞22回复举报 -
自然语言处理研究对象有哪些
自然语言处理(NLP)的研究对象是计算机与人类语言之间的交互。它的工作是理解人类语言并将其转换为机器语言。
,市场前景巨大。近年来,自然语言处理处于快速发展状态。互联网和移动互联网以及世界经济社会一体化趋势对自然语言处理技术的迫切需求,这为自然语言处理研发提供了强大的市场力量。
从目前自然语言处理技术的研究发展趋势和情况来看,以下研究方向或问题可能是未来自然语言处理研究必须攻克的堡垒语言处理:
1.词法、句法分析:包括详细分词、新词发现、词性标注等;
2非标准文本的意义消歧和语义分析;
3。语言的认知模型:例如,使用深度神经网络处理自然语言并创建更有效和可解释的语言计算模型。;
4.知识图谱:如何构建大规模、高精度的知识图谱,进行逻辑学习和符号表示;
5、半监督和无监督学习,分类和聚类都能准确完成;
6信息抽取:如何从多源异构信息中准确抽取关系和事件。
7情感分析:包括基于上下文感知的情感分析、跨领域、跨语言的情感分析、基于深度学习的端到端情感分析、情感分析。解读、反讽分析、立场分析等;
8.如何评价信息单元的重要性;
9.信息检索:包括意图搜索、语义搜索等,可能出现在各种场景的垂直领域,将通过基于自然语言多媒体交互的方法论知识推理、智能搜索和推荐技术进行;
10自动问答:包括深度推理问答、多轮问答等多种形式的自动问答系统。;
11机器翻译:包括小数据机器翻译、非标准文本机器翻译和章节级机器翻译。
 赞51回复举报
赞51回复举报 -
人工智能自然语言处理现在能做些什么?到目前为止,所有基于统计和深度学习的文本语义提取只能说是自然语言处理,而不是自然语言理解。
举个简单的例子,我们想让HE理解“太阳从东方升起”这句话,但是什么是“太阳”,什么是“东”,“东”是什么意思?目前的人工智能都不知道。现在的AI可以通过word2vec知道“太阳”相当于“太阳的头”,而“东”有“西”、“南”、“北”的同义词……而“东”必须是动词。但他就像一个盲人,无法理解正常人所理解的“太阳”。为了让人工智能理解“太阳”,我们要么给它配备一个摄像头,把它对准太阳,像小孩子一样教它理解一些东西,要么我们用大量太阳的照片来训练它,这样人工智能获得了像人类一样对“太阳”的理解。但这种认识仍然是片面的,因为他感受不到阳光的耀眼、阳光的温暖、阳光驱散黑暗或被黑暗吞噬的过程。为了获得类似人类的理解,人工智能还应该具有光强度传感器和温度传感器。在训练这个模型时,我们不仅应该使用静态照片,还应该使用动态视频,让它理解“上”、“下”等动作的含义。当让AI理解“东方”时,电子罗盘可能不如“旭日东升的方向”那么接近人类认知。有了这些基本的认识,利用知识提高自己对太阳的认识,比如太阳与地球的距离、太阳的大小、太阳的温度、太阳内部核聚变产生的过程等。能量,还有关于太阳的神话传说(夸父追太阳,后羿追太阳),文学传说(两个孩子围着太阳吵架)……在这一点上,AI对太阳的理解至少和我们中国人很相似对太阳的了解。通过迁移学习的方法,AI可以从图片、声音和视频中学习我们的现实世界,然后设置机器人大脑中学习到的神经元的参数,让机器人在现实世界中继续学习。估计只有真正学会了意义,才能真正达到机器的意义。
利用这种方法,机器可以理解沐浴在阳光下的身体的温暖,但却无法理解人类灵魂此刻感受到的喜悦。当然,也可以设置最佳温度和程序来模拟接近最佳温度时阳光照射到传感器上的愉悦感。然而,将快乐、痛苦、悲伤、愤怒和其他人类特有的情感数字化并不是一件简单的事情。电量、环境温度、湿度和噪音都可以作为衡量快乐和痛苦的指标。悲伤和愤怒是很难的。更困难的是如何让这些情感与人类的情感产生共鸣,让机器能够理解人类的悲伤。
我一直觉得,如果一个机器人拥有我们人类所有的感官(模拟饥饿能消耗的电量),并且有100亿个神经元连接到这些感官,加上未来CNN+LSTM的发展通过深度神经网络架构,人们可以像养育孩子一样养育一个能够真正理解世界、理解自然语言的机器人。传感器+黑匣子的深度神经网络通常的结果就是意识的产生。但那一刻对于我们人类来说也是最危险的时刻,因为我们创造了超人,但法律却没有办法阻止他。他的大脑对我们来说就是一个黑匣子,用机器人三定律来约束他,比用定律来约束人类要弱。(稍微跑题了)
回到这个话题,根据黄培宏回答中的链接,机器一旦理解了“意义”,还需要理解一些基本的“原理”,才能真正理解自然语言。例如,机器需要知道大接近和非常小接近的原理,才能一致地解释为什么图片中太阳与房子的关系如此扭曲。她必须了解多色光在大气中的折射和散射原理,才能回答两个孩子争论太阳的悖论。但如何让机器理解真相、学会推理并表述出来,就需要机器学习的高手了。我之前想知道机器是否可以学习物理守恒定律,例如能量和动量守恒定律、角动量守恒定律、电荷守恒定律、重子数守恒定律等。如果电子和正电子湮灭产生的最终态粒子的光谱被用来训练机器(如果它能够学习的话),它将从如此多的参数中推导出这些物理定律。也许这个想法是让机器了解真相的一种方式。用移动更远、变小的人、汽车和动物来训练它理解“近大远小”的原理
答案可能对你有帮助。 赞65回复举报
赞65回复举报
.jpg)
.jpg)
.jpg)
相关资讯
更多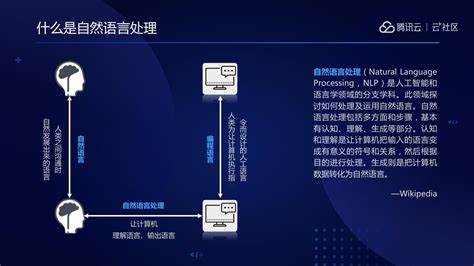



热门新闻
-
 由他
由他
<noframes date-time="5C6C23"> 2003位用户围观了该问题 -
 肖肖
474位用户围观了该问题
肖肖
474位用户围观了该问题 -
 那一抹蓝
465位用户围观了该问题
那一抹蓝
465位用户围观了该问题







