知识图谱构建的主要问题(知识图谱的应用主要有哪两个)
作者:顿季苍 | 发布日期:2024-07-12 03:46:29
2、 知识图谱的构建是一个迭代优化的过程,需要不断地根据实际情况调整数据收集、实体识别、关系抽取等环节的策略和方法,以确保图谱的质量和实用性。 随着技术的不断进步和应用场景的不断拓展,知识图谱将在更多领域发挥重要作用。
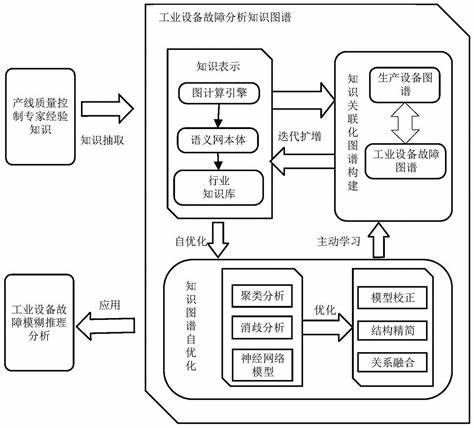
3、 知识图谱的基本组成三要素:实体、属性、关系。 实体-关系-实体 三元组;实体-属性-属性值三元组。 目前的知识图谱分为两类。 一类是开放域的知识图谱,另一类是垂直领域的知识图谱。 比如谷歌为搜索引擎所建立的知识图谱就属于开放域的。 垂直领域的知识图谱,比如说金融的,电商的。 首先就是要先处理数据。
5、 本篇文章主要从应用角度来聊一聊如何构建schema以及shcema构建中需要考虑的问题。 以下所讲的schema构建主要是基于common sense进行构建的,弱关系图谱构建会在应用中讲到。 简单来说,一个知识图谱的schema就是相当于一个领域内的数据模型,包含了这个领域里面有意义的概念类型以及这些类型的属性。
4、 知识图谱的构建是一个多步骤的过程,它涉及数据收集、处理、关系抽取、验证及可视化等环节。 构建知识图谱的首要步骤是数据收集,这一过程需要从各种来源获取相关信息。 例如,在构建一个关于历史人物的知识图谱时,可能需要从史书、研究文献、网络资源等渠道收集数据。
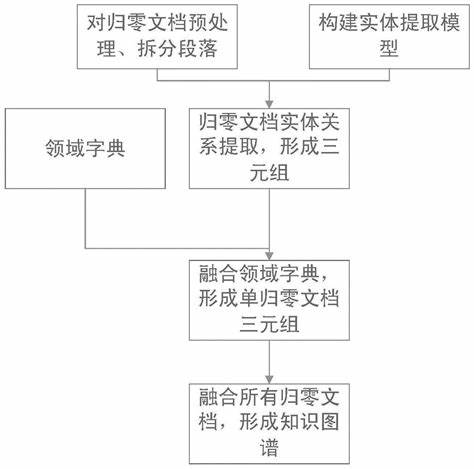
1、 通常情况下,我们会按照结构模型把系统产生的数据分为三种类型:结构化数据、半结构化数据和非结构化数据。 结构化数据,即行数据,是存储在数据库里,可以用二维表结构来逻辑表达实现的数据。 最常见的就是数字数据和文本数据,它们可以某种标准格式存在于文件或记录的固定字段中。 相对应的,没有固定结构不方便用数据库二维逻辑表来表现的数据即称为非结构化数据,包括所有格式的办公文档、文本、图片、XML、HTML、各类报表、图像和音频/视频信息等等。
