语音识别用什么算法
- 语音识别
- 2024-05-17 22:59:33
- 2386
一般来说,语音识别的方法有三种:基于声道模型和语音知识的方法、模板匹配的方法以及利用人工神经网络的方法。 该方法起步较早,在语音识别技术提出的开始,就有了这方面的研究,但由于其模型及语音知识过于复杂,现阶段没有达到实用的阶段。

DTW是动态时间规整算法,在语音识别系统中通常用于特定人识别,特定人识别即A用户使用这个语音识别系统,B用户使用就会出现语音识别出错或无法识别的现象。 DTW在语音识别系统中,是一个需要用户事先训练的系统。
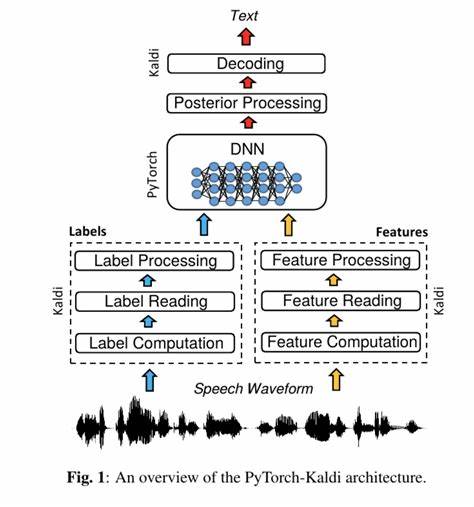
在解码阶段,Viterbi算法如同寻宝图,通过动态规划找出最佳的语音路径。 这个过程中的累积概率由三部分构成:观察概率,即声学模型对帧状态转移的预测;语言概率,统计语言模型提供的词汇分布,对于提高识别准确率至关重要;而语言模型过大时,可能会导致无模型识别的混乱局面。
语音识别步骤使用机器学习算法,将特征提取出来的信息与语音库中的信息进行匹配,进而得到文本。 这些算法包括HMM,DNN,RNN,CTC,Transformerandsoon。

声音识别,又称语音识别,是一种计算机技术,可以将说话人的语音转换为文本。 这需要结合语音信号处理、语音识别算法和自然语言处理技术。 语音信号处理包括语音采集、预处理、特征提取和语音压缩。 语音采集包括使用话筒将语音转换为电信号,并将其转换为数字信号。 预处理包括去噪、去除干扰和消除偏移。

上一篇:语音识别技术通俗解释
下一篇:语音识别的基本原理概述












热门文章

机械设计制造及自动化考研都考啥
2024-05-17 22:24:33
人工智能对学生的弊端
2024-05-17 22:22:48
张雪峰谈机械电子与自动化专业
2024-05-17 22:17:32
四十多岁搞自动化找工作难不难
2024-05-17 22:15:48
数据分析一个月挣多少钱啊
2024-05-17 22:10:33
东莞智勇自动化薪资待遇怎么样
2024-05-17 22:05:18
中科院自动化所2024校招
2024-05-17 22:01:48
2024电气工程及其自动化招聘信息
2024-05-17 22:00:03
2024年非标自动化行业
2024-05-17 21:54:47
大专电气自动化需要学哪些课程
2024-05-17 21:49:33