最全知识图谱综述
还可以输入1000字
全部回答(1)
最佳回答
技术|知识图谱构建关键技术点梳理本文主要内容由两篇有代表性的知识图谱综述整理而成:
1.徐增林,盛永攀,何立荣,王亚芳。 知识图谱技术综述[J].电子科技大学学报(第4期):589-606。
2.刘巧,李阳,段宏,等。 知识图谱构建技术综述[J].计算机研究与发展,2016(3):582-600,共19页。
文章从知识图谱的定义和技术架构入手,对知识图谱进行了自下而上的全面分析。 构建知识图谱涉及的关键技术。 本文是涉及到的技术点列表,个别技术点稍后会一一整理。
1.1解决的问题
如何从半结构化和非结构化数据中提取实体、关系、实体属性等结构化信息。
1.2涉及的关键技术
1.2.1实体提取
又称NamedEntityRecognition(NER),是指从文本数据中集中提取数据自动识别命名实体。
1.2.2关系抽取
关系抽取是指从相关语料中抽取实体之间的关系,通过关系将实体(概念)连接起来。
1.2.3属性提取
指从不同信息源采集特定实体的属性信息,如提取公众的昵称、生日、国籍、教育背景等图和其他信息。
2.1解决的问题
将现实世界中的各类知识表达成计算机可以存储和计算的结构。
2.2涉及的关键技术
传统的知识表示方法主要采用RDF(ResourceDescriptionFramework资源描述框架)三元组SPO(主体、属性、客体)来符号化来描述之间的关系近年来,以深度学习为代表的表征学习技术也取得了重要进展。
3.1解决的问题
信息抽取结果可能包含大量冗余和错误信息,数据之间的关系也比较扁平,缺乏层次和逻辑。 通过知识融合,可以消除概念模糊,消除冗余和误解,保证知识质量。
3.2关键技术
3.2.1实体链接
指将从文本中提取的实体对象链接到知识库上的相应操作正确的实体对象。 主要涉及两个方面:
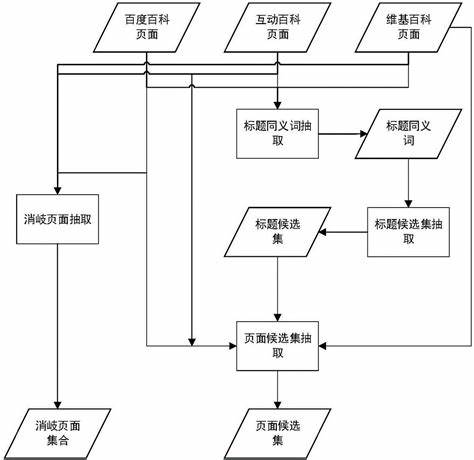
▪实体消歧
用于解决同名实体歧义问题的技术。 例如,“李娜”(所指)可以对应于作为歌手的实体李娜,也可以对应于作为网球运动员的实体李娜。
▪共指解析EntityResolution
又称实体对齐(objectalignment)、实体匹配(entitymatching)、实体同义词(entitysynonyms)等,用于解析多个所指项对应同一个实体对象的问题。 例如,在新闻稿中,“BarackObama”、“pre sidentObama”、“thepre sident”和其他指示物都可以指同一实体“Obama”。
3.2.2知识融合
指从第三方知识库产品或现有的结构化数据中获取知识输入。
4.1解决的问题
信息抽取和知识融合可以得到一系列基本的事实表达。 但事实并不等于知识。 最终获得结构化、网络化的知识体系,还需要经过知识加工的过程。
4.2涉及的关键技术
4.2.1本体提取
本体是对概念建模的规范,是描述目标的抽象模型以正式的方式清楚地定义概念及其之间的联系的世界。
4.2.2知识推理
指从知识库中已有的实体关系数据出发,通过计算机推理建立实体之间新的关联,从而扩展和丰富知识网络。
4.2.3质量评估
量化知识的可信度,通过丢弃置信度较低的知识来保证知识库的质量。
5.1解决的问题
知识图谱的内容需要与时俱进,其构建过程是一个不断迭代、更新的过程。 主要包括概念的更新和数据层的更新。
▪数据层更新:主要是添加或更新实体、关系、属性值等。
▪Schema层更新:指添加新的内容后得到新的Schema。 数据,新的模式需要自动添加到知识库的模式层。 基于知识的NLG综述在ChatGPT的明亮光环下,大型模型的潜力再次被证明,其对NLP领域的深远影响也逐渐显现。 以下是他们如何重塑实验室研究、公司竞争、研究重点和行业动态的一些关键点的详细介绍:
1.**实验室发现的转变**:资源A.有限的研究机构正在关注快速解释和整合知识的能力,特别是在特定任务中。 他们强调提示的清晰性和模型内部知识的有效利用,特别是小任务和大任务的结合。
2.**大型模型竞赛**:商业实验室的竞争日益激烈,强化学习(RLHF)和大规模知识整合成为研究热点。 保密性增加,对高技能人员的需求增加,小任务被巧妙地集成到大型模型系统中,以提高整体性能。
3.**定位新的研究焦点**:从追求大模型的无所不在到研究知识的局限性,挖掘知识和自学习已经成为最前沿的趋势技术。 资金投入和就业市场也有相应的调整。 算法工程师的职位可能面临挑战,而架构和大数据工程师的职位则变得越来越重要。
4.**知识的创新与应用**:ChatGPT的RLHF策略优化了知识质量,内外部知识的整合变得至关重要。 如今,文本生成不再单纯依赖文本输入,外部知识的获取和整合已成为核心竞争力。
5.**技术和职业的变化**:资本倾向于支持大型建模项目,这推动了算法的角色转变,而对建筑工程师的需求日益增加。 知识创新的重点是区分和有效利用内部和外部的知识来源。 例如,注意力机制可以取代记忆和OOV方法。
这些变化不仅影响了自然语言处理(NLP)技术的发展,也引起了视觉计算(CV)领域和专业市场的深刻调整,推动了高效知识的新方法。 利用和模型合成时代。
文本生成不再局限于知识库,而是结合内部和外部知识,通过增强深度学习模型(例如神经表示学习)来提高所生成文本的可解释性和质量。 研究人员探索将输入文本中的信息与维基百科等知识库相结合,以创建更丰富、更连贯的输出,例如对话、摘要和句子故事。
创建知识增强文本的挑战包括知识获取和有效整合通过注意力机制和复制/指向机制,模型可以灵活地整合内部和外部知识。 外部知识,例如知识图和知识库,为选择主题、提取摘要关键信息以及在对话中应用常识提供了基础。
值得注意的是,知识源分为内部(输入文本)和外部(知识图谱等),这扩展了机器创建文本的可能性,使其更接近人类。 沟通方法。 此外,PPLM等技术允许在推理阶段包含特定知识来调节语言生成。
在基于主题的高级NLG中,研究人员通过在主题模型中生成关键信息、将深度学习模型与主题相结合并使用神经主题模型来提高生成文本的质量。 这些方法强调关键词在创建对话系统中的关键作用,它们提供信息指导并改善底层模型的控制和信息保留。
综上所述,知识增强NLG是一个多维度的研究领域,涉及知识整合、应用技术、模型优化以及知识获取和整合的挑战。 通过详细的案例研究和基准分析,我们希望推动该领域未来的进步,实现更有效的知识利用和模型组合。
1.徐增林,盛永攀,何立荣,王亚芳。 知识图谱技术综述[J].电子科技大学学报(第4期):589-606。
2.刘巧,李阳,段宏,等。 知识图谱构建技术综述[J].计算机研究与发展,2016(3):582-600,共19页。
文章从知识图谱的定义和技术架构入手,对知识图谱进行了自下而上的全面分析。 构建知识图谱涉及的关键技术。 本文是涉及到的技术点列表,个别技术点稍后会一一整理。
1.1解决的问题
如何从半结构化和非结构化数据中提取实体、关系、实体属性等结构化信息。
1.2涉及的关键技术
1.2.1实体提取
又称NamedEntityRecognition(NER),是指从文本数据中集中提取数据自动识别命名实体。
1.2.2关系抽取
关系抽取是指从相关语料中抽取实体之间的关系,通过关系将实体(概念)连接起来。
1.2.3属性提取
指从不同信息源采集特定实体的属性信息,如提取公众的昵称、生日、国籍、教育背景等图和其他信息。
2.1解决的问题
将现实世界中的各类知识表达成计算机可以存储和计算的结构。
2.2涉及的关键技术
传统的知识表示方法主要采用RDF(ResourceDescriptionFramework资源描述框架)三元组SPO(主体、属性、客体)来符号化来描述之间的关系近年来,以深度学习为代表的表征学习技术也取得了重要进展。
3.1解决的问题
信息抽取结果可能包含大量冗余和错误信息,数据之间的关系也比较扁平,缺乏层次和逻辑。 通过知识融合,可以消除概念模糊,消除冗余和误解,保证知识质量。
3.2关键技术
3.2.1实体链接
指将从文本中提取的实体对象链接到知识库上的相应操作正确的实体对象。 主要涉及两个方面:
▪实体消歧
用于解决同名实体歧义问题的技术。 例如,“李娜”(所指)可以对应于作为歌手的实体李娜,也可以对应于作为网球运动员的实体李娜。
▪共指解析EntityResolution
又称实体对齐(objectalignment)、实体匹配(entitymatching)、实体同义词(entitysynonyms)等,用于解析多个所指项对应同一个实体对象的问题。 例如,在新闻稿中,“BarackObama”、“pre sidentObama”、“thepre sident”和其他指示物都可以指同一实体“Obama”。
3.2.2知识融合
指从第三方知识库产品或现有的结构化数据中获取知识输入。
4.1解决的问题
信息抽取和知识融合可以得到一系列基本的事实表达。 但事实并不等于知识。 最终获得结构化、网络化的知识体系,还需要经过知识加工的过程。
4.2涉及的关键技术
4.2.1本体提取
本体是对概念建模的规范,是描述目标的抽象模型以正式的方式清楚地定义概念及其之间的联系的世界。
4.2.2知识推理
指从知识库中已有的实体关系数据出发,通过计算机推理建立实体之间新的关联,从而扩展和丰富知识网络。
4.2.3质量评估
量化知识的可信度,通过丢弃置信度较低的知识来保证知识库的质量。
5.1解决的问题
知识图谱的内容需要与时俱进,其构建过程是一个不断迭代、更新的过程。 主要包括概念的更新和数据层的更新。
▪数据层更新:主要是添加或更新实体、关系、属性值等。
▪Schema层更新:指添加新的内容后得到新的Schema。 数据,新的模式需要自动添加到知识库的模式层。 基于知识的NLG综述在ChatGPT的明亮光环下,大型模型的潜力再次被证明,其对NLP领域的深远影响也逐渐显现。 以下是他们如何重塑实验室研究、公司竞争、研究重点和行业动态的一些关键点的详细介绍:
1.**实验室发现的转变**:资源A.有限的研究机构正在关注快速解释和整合知识的能力,特别是在特定任务中。 他们强调提示的清晰性和模型内部知识的有效利用,特别是小任务和大任务的结合。
2.**大型模型竞赛**:商业实验室的竞争日益激烈,强化学习(RLHF)和大规模知识整合成为研究热点。 保密性增加,对高技能人员的需求增加,小任务被巧妙地集成到大型模型系统中,以提高整体性能。
3.**定位新的研究焦点**:从追求大模型的无所不在到研究知识的局限性,挖掘知识和自学习已经成为最前沿的趋势技术。 资金投入和就业市场也有相应的调整。 算法工程师的职位可能面临挑战,而架构和大数据工程师的职位则变得越来越重要。
4.**知识的创新与应用**:ChatGPT的RLHF策略优化了知识质量,内外部知识的整合变得至关重要。 如今,文本生成不再单纯依赖文本输入,外部知识的获取和整合已成为核心竞争力。
5.**技术和职业的变化**:资本倾向于支持大型建模项目,这推动了算法的角色转变,而对建筑工程师的需求日益增加。 知识创新的重点是区分和有效利用内部和外部的知识来源。 例如,注意力机制可以取代记忆和OOV方法。
这些变化不仅影响了自然语言处理(NLP)技术的发展,也引起了视觉计算(CV)领域和专业市场的深刻调整,推动了高效知识的新方法。 利用和模型合成时代。
文本生成不再局限于知识库,而是结合内部和外部知识,通过增强深度学习模型(例如神经表示学习)来提高所生成文本的可解释性和质量。 研究人员探索将输入文本中的信息与维基百科等知识库相结合,以创建更丰富、更连贯的输出,例如对话、摘要和句子故事。
创建知识增强文本的挑战包括知识获取和有效整合通过注意力机制和复制/指向机制,模型可以灵活地整合内部和外部知识。 外部知识,例如知识图和知识库,为选择主题、提取摘要关键信息以及在对话中应用常识提供了基础。
值得注意的是,知识源分为内部(输入文本)和外部(知识图谱等),这扩展了机器创建文本的可能性,使其更接近人类。 沟通方法。 此外,PPLM等技术允许在推理阶段包含特定知识来调节语言生成。
在基于主题的高级NLG中,研究人员通过在主题模型中生成关键信息、将深度学习模型与主题相结合并使用神经主题模型来提高生成文本的质量。 这些方法强调关键词在创建对话系统中的关键作用,它们提供信息指导并改善底层模型的控制和信息保留。
综上所述,知识增强NLG是一个多维度的研究领域,涉及知识整合、应用技术、模型优化以及知识获取和整合的挑战。 通过详细的案例研究和基准分析,我们希望推动该领域未来的进步,实现更有效的知识利用和模型组合。
2